
分类: AI
-
Deepseek-GPU版-本地跑起来啦!
成功啦!
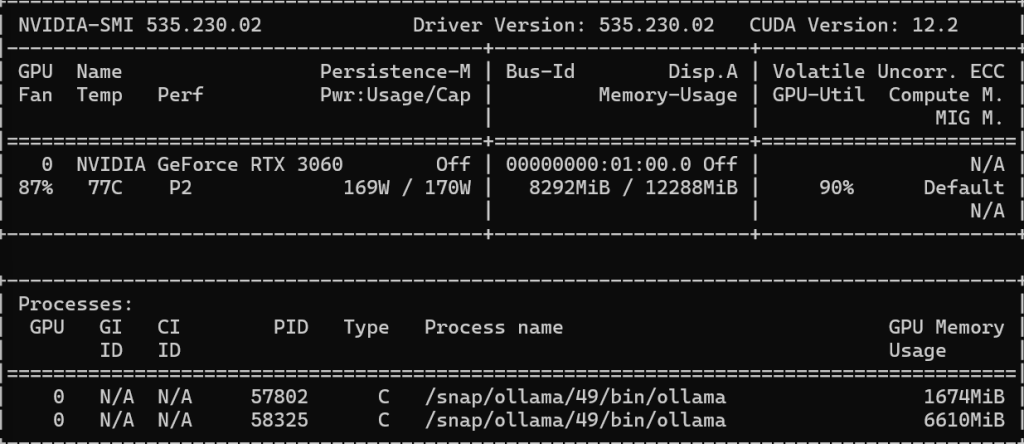
坑点1. 是Ollama 先与GPU安装,GPU插上去之后,总是会调用CPU而不是GPU
坑点2. 国内Ollama官方 下载的速度,绝了大部分重装的勇气官方安装路径: curl -fsSL https://ollama.com/install.sh | sh
解决方法: snap 安装 (缺点是只能装到0.9.0,官方应该是0.9.2)
sudo snap install ollama关于GPU内存使用:
1.7G的是 允许的deepseek-r1:1.5b的模型
6.7G的是deepseek-r1:8B的模型
速度真的快https://msw.mba/ -
通用提示词框架
七大核心维度
Role(角色) – Task(任务) – Tone(语气) – Context(背景) – Format(输出格式) – Criteria(验收) – Iteration(迭代方向)
角色- Role: 明确 AI 在交互中的身份设定,决定输出的专业立场与行为模式
- 关键作用:
- 约束 AI 的知识调用范围(如「医学顾问」需遵循循证医学标准)
- 规范表达风格(如「营销文案写手」需使用煽动性语言)
- 常见角色模板:角色类型典型场景核心要求领域专家学术研究、技术方案设计严谨术语、数据支撑创意顾问广告文案、故事创作想象力、修辞多样性问题解决者故障排查、决策建议逻辑链条、备选方案优先级教育者知识科普、习题解析循序渐进、类比说明
- 示例:「你是一位专注于新能源领域的投资分析师」
任务目标(Task)用可量化的标准描述 AI 需要完成的具体工作
- 黄金法则:
- 动词开头:使用「分析」「生成」「优化」等明确动作词
- 结果可验证:避免「提供有用信息」,改为「列出 3 个可行性方案」
- 复杂度分层:对多阶段任务使用「首先… 其次… 最终…」
- 错误与正确对比:
- 模糊任务:「帮我写篇营销文案」
- 精准任务:「生成 3 条针对 25-35 岁女性的护肤品朋友圈文案,每条包含痛点场景 + 产品卖点 + 行动指令,风格需年轻化、有共鸣」
语气风格(Tone)设定输出内容的情感色彩与表达口吻
- 维度分解:
- 正式程度:从「学术严谨」到「口语化闲聊」
- 情感倾向:积极 / 中立 / 批判性
- 表达力度:温和建议 / 强烈说服 / 幽默调侃
- 场景化匹配示例:应用场景推荐语气禁忌风格企业年报摘要客观中立、数据导向夸张修辞、主观评价社交媒体互动亲切活泼、表情符号辅助专业术语堆砌危机公关声明诚恳致歉、解决方案导向模糊其辞、推卸责任
背景信息(Context)提供任务相关的历史数据、约束条件或上下文场景
- 信息分层策略:
- 基础层:必要前提(如「基于 2024 年中国新能源汽车销量数据」)
- 限制层:边界条件(如「预算不超过 50 万元」)
- 启发层:参考案例(如「风格参考《流浪地球》的科技感描述」)
- 案例:“你需要为一家连锁咖啡店设计新品推广方案。背景:品牌主打「第三空间」概念,目标客群为 25-40 岁都市白领,2024 年同类产品均价 38 元,本次新品成本较传统咖啡高 20%。”
输出格式(Format)指定结果的呈现形式,提升信息可读性
- 常用格式类型:
- 结构化:表格、清单、流程图
- 创意化:诗歌、对话体、分镜脚本
- 学术化:SWOT 分析、PEST 模型、参考文献格式
- 示例:“请以思维导图形式呈现营销策略,包含目标人群、渠道选择、促销活动 3 个主分支,每个分支下至少展开 2 个子节点。”
评估标准(Criteria)设立结果验收的量化指标
- 设计方法:
- 数量指标:「生成不少于 5 个方案」
- 质量指标:「方案需通过 ROI>1.5 的筛选」
- 合规指标:「内容需符合广告法第 9 条规定」
- 应用场景:“方案需满足:① 线上转化率提升 20% 以上;② 预算控制在推广费用的 30% 以内;③ 不得使用「最」「第一」等极限词。”
迭代指令(Iteration)引导 AI 进行多轮优化的提示
- 典型用法:
- 正向迭代:「在方案二的基础上增加线下渠道拓展建议」
- 负向迭代:「删除所有涉及明星代言的内容」
- 对比迭代:「生成 A 版本(保守型)和 B 版本(激进型)两个方案」
高质量提示词的黄金写作法则 – 六大法则
金字塔法则:从宏观到细节分层构建
- 顶层:角色与任务(如「你是电商运营专家,需优化店铺首页」)
- 中层:背景与约束(「店铺主营母婴用品,客单价 200-500 元,转化率低于行业均值 15%」)
- 底层:格式与标准(「以 PPT 大纲形式呈现,包含流量入口优化、信任背书设计、促销模块重组 3 个部分」)
具体化法则:消除所有模糊表述
- 错误示范:「写一篇关于人工智能的文章」
- 优化版本:“撰写一篇面向企业管理者的 AI 趋势分析文章,需包含:
- 2024 年 AI 在供应链管理中的 3 个落地案例;
- 中小企业部署 AI 的成本效益分析(附数据图表);
- 未来 2 年 AI 对管理决策的潜在冲击预测;
风格要求:专业但非技术化,每 200 字插入 1 个类比说明。”
示例锚定法则:用案例降低理解偏差
- 应用场景:当涉及主观判断(如「年轻化设计」「科技感」)时
- 模板:“参考以下示例的风格进行创作:
[示例 1] 原句:传统咖啡机操作复杂 → 改写:一键搞定,小白也能当咖啡师
[示例 2] 原句:产品性能稳定 → 改写:7×24 小时不间断运行,零故障记录
请按照上述「痛点场景 + 解决方案」的结构,改写剩余 10 条产品描述。”
约束 – 自由平衡法则:在限制中激发创造力
- 双向设计:
- 约束项:「预算不超过 10 万元」「必须使用现有物流体系」
- 创新项:「探索 3 种非传统营销渠道」「提出颠覆行业的定价模型」
- 案例:“在不增加研发预算的前提下,设计 3 种能使产品故障率降低 50% 的改进方案,允许突破现有材料体系,但需符合 ISO9001 认证标准。”
多轮引导法则:分阶段控制思考深度
- 首轮:广度探索(「列出 10 个可能的市场拓展方向」)
- 次轮:深度挖掘(「针对方向三,分析其政策风险与消费者接受度」)
- 终轮:方案成型(「基于以上分析,生成详细执行计划,包含时间表与 KPI」)
反馈校准法则:建立结果验收机制
- 验收框架:
- 事实性校验:「数据来源是否标注清楚?」
- 逻辑性校验:「因果推导是否存在跳跃?」
- 需求匹配度:「是否解决了最初提出的 3 个核心问题?」
- 示例:“请检查方案是否满足:
√ 包含 3 个以上可量化的执行指标
√ 每个策略都有对应的风险预案
√ 引用至少 2 篇 2024 年的行业报告作为依据”
跨场景提示词框架应用实例
学术研究场景
角色:你是经济学领域的文献综述专家 任务:撰写「数字经济对就业市场影响」的文献综述框架 背景:已收集2019-2024年中英文文献50篇,重点关注中国市场 语气:严谨客观,采用学术规范表述 输出格式:思维导图(需包含理论基础、影响机制、争议焦点、研究空白4个主模块) 评估标准:框架需覆盖至少80%已收集文献的研究视角,争议焦点部分需列出至少3种对立观点 迭代指令:完成后请补充「政策建议」子模块,并标注每个建议对应的理论依据商业策划场景
角色:你是新零售业态创新顾问 任务:为传统超市设计数字化转型方案 背景:超市位于二线城市核心商圈,面积2000㎡,目标客群年龄35-55岁,2023年线上订单占比仅8% 语气:务实可行,突出投入产出比 输出格式:PPT提案(包含现状分析、改造方案、投资回报表3个部分) 评估标准:方案需实现线上订单占比提升至30%,改造成本控制在500万元以内 迭代指令:先提交3个方向的创意简报,经筛选后再展开详细方案创意写作场景
角色:你是科幻小说作家,擅长硬科幻与社会伦理结合的题材 任务:创作一个关于「记忆移植技术」的短篇故事开头 背景:设定在2045年的智慧城市,记忆移植已成为治疗心理创伤的常规手段,但存在伦理争议 语气:冷峻细腻,兼具科技质感与人文关怀 输出格式:小说片段(300-500字),需包含场景描写、主角心理活动、技术细节暗示 评估标准:需在开头50字内建立世界观悬念,技术描述需符合认知科学基本原理 迭代指令:提供A版本(主角接受记忆移植)和B版本(主角拒绝移植)两个开头提示词优化迭代流程
- 初始提示词:基于框架完成基础构建
- 首轮输出:记录 AI 响应中的偏差点(如信息遗漏、格式错误)
- 问题归类:区分「角色错位」「任务模糊」「约束缺失」等问题类型
- 针对性优化:补充缺失要素或调整描述方式
- 对比测试:使用 A/B 测试验证不同提示词版本的效果
- 经验沉淀:建立提示词模板库,按场景分类存储
- 关键作用:
-
AI 提示词优化的CREATE 框架
反事实推理是Deepseek 的核心技术之一, 通过构建与事实相反的假设性情景,来探索因果关系和潜在结果的逻辑推理方法。
反事实推理有着严密的数学模型,基于因果推断三层次模型,由美国计算机科学家 Pearl 提出。
因果推断三层次分别为关联、干预和反事实。
关联层关注条件概率,能发现变量间相关性,但无法确定因果性;
干预层关注主动干预某一变量后对结果的影响;
反事实层则研究假设性问题,关注如果采取了不同的行动,结果会如何,会用到结构因果建模、反事实计算、可识别性分析等知识。
参考deepseek 的反事实推理的逻辑,我们来看CREATE 框架
Contrast: 要求多方案比较
Risk Aware: 要求评估潜在风险
Experimental: 要求假设推演
Alternative: 要求备选方案
Trade off: 要求分析优缺点
Explain: 要求说明决策逻辑
-
使用MCP Market
火山: https://www.volcengine.com/mcp-marketplace
Trae 里面直接使用 @Build with MCP 可以打开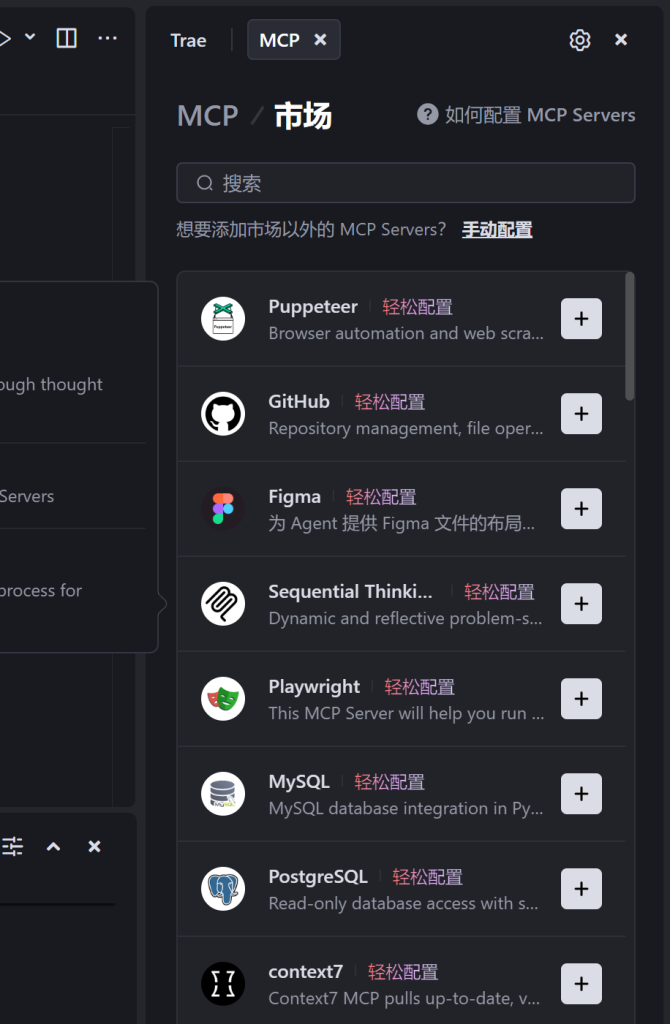
MCP 市场: http://mcpmarket.cn/ -
基于Deepseek,搭建本地知识库
基础环境:Windows, Anaconda, DockerChat 大模型:deepseek-r1:1.5b
知识库:Open Web UI
先配置基础环境
下载Anaconda:https://www.anaconda.com/download/success
安装并被指国内镜像: https://mirrors.tuna.tsinghua.edu.cn/help/anaconda/
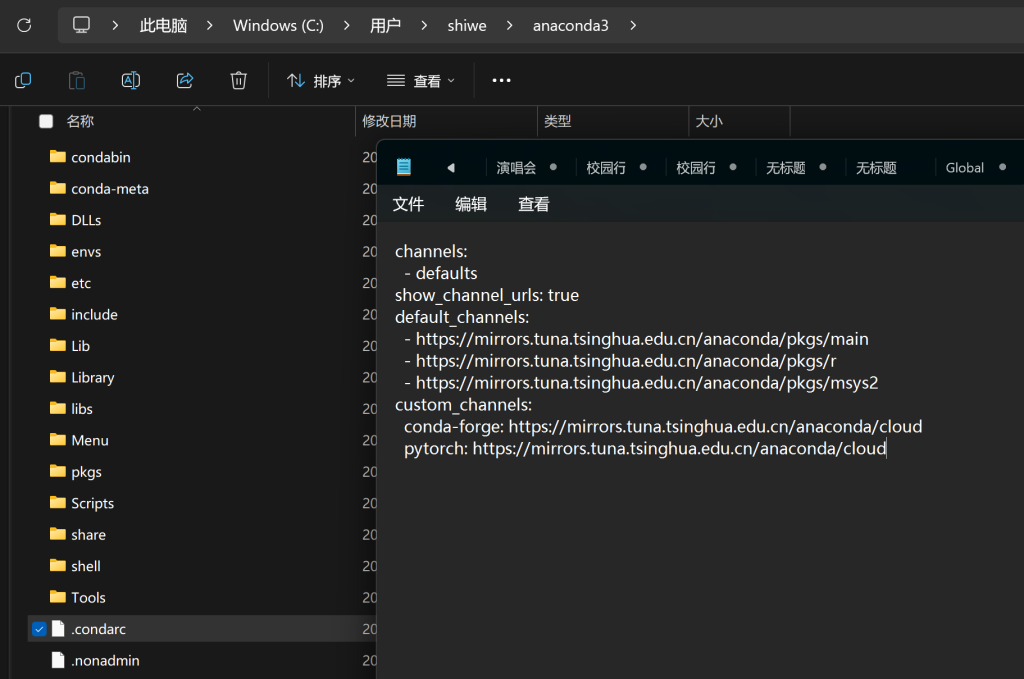
# 创建名为ai_knowledge的环境 conda create -n ai_knowledge -y conda activate ai_knowledge
下载并安装 ollama,全默认就可以模型的版本在这里找
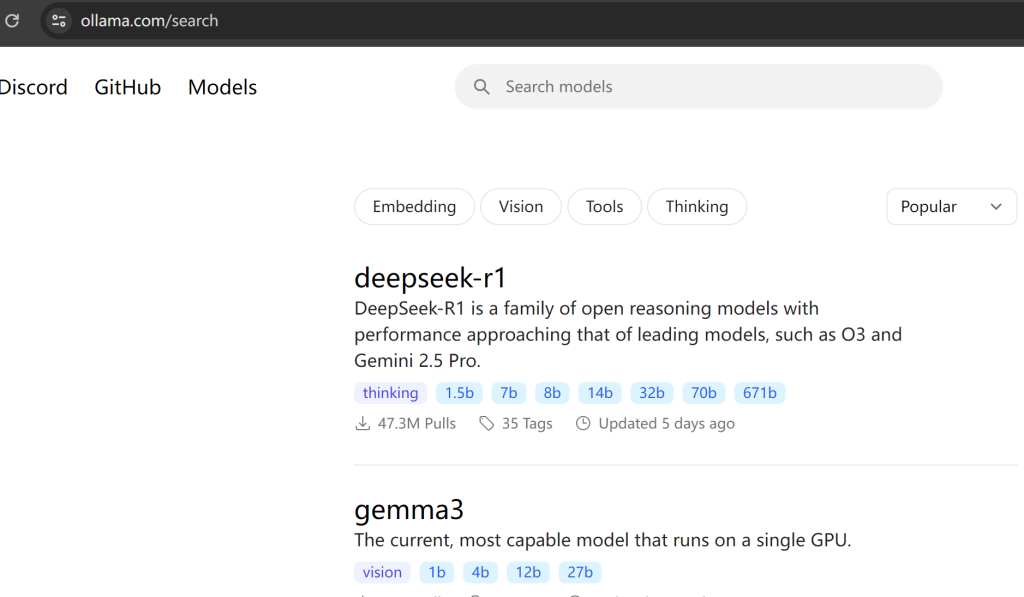
# 下载模型 ollama pull deepseek-r1:1.5b # powershell 启动 ollama 服务 Start-Process -FilePath "ollama" -ArgumentList "serve" -NoNewWindow
这里也可以通过run 命令启动,同时可以打开ollama的对话窗口

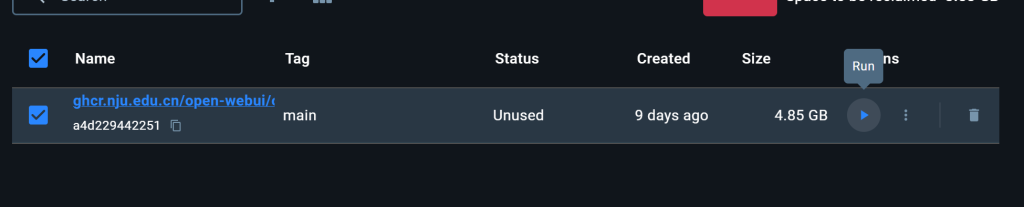
下载并安装好docker desktop,一路店到底#下载 并运行 open webUI docker pull ghcr.nju.edu.cn/open-webui/open-webui:main docker run -d -p 3000:8080 --restart no -v open-webui:/app/backend/data --name open-webui ghcr.nju.edu.cn/open-webui/open-webui:main或者直接点图中的run 来运行
打开 http://localhost:3000/auth?redirect=%2F
Open WebUI 自动与本地的ollama 连接好了
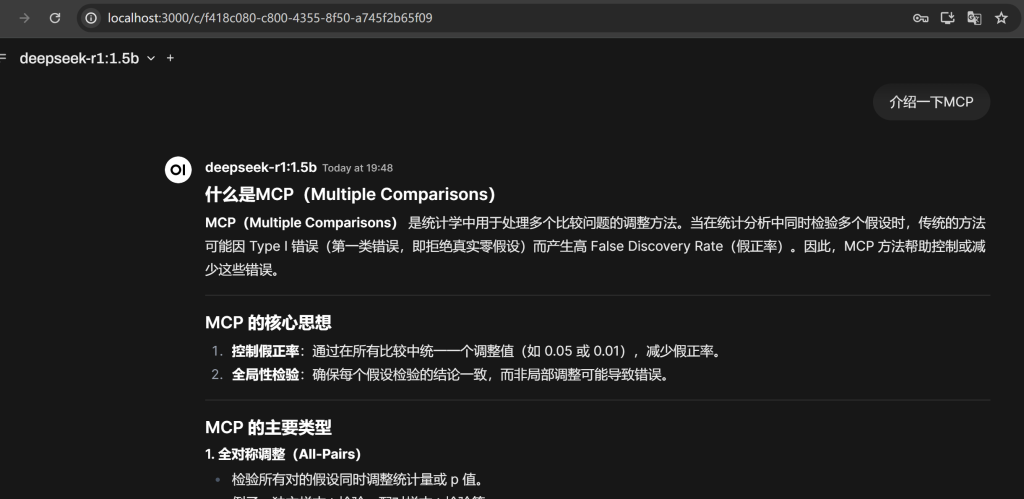
测试一下效果
开始创建知识库,看步骤1234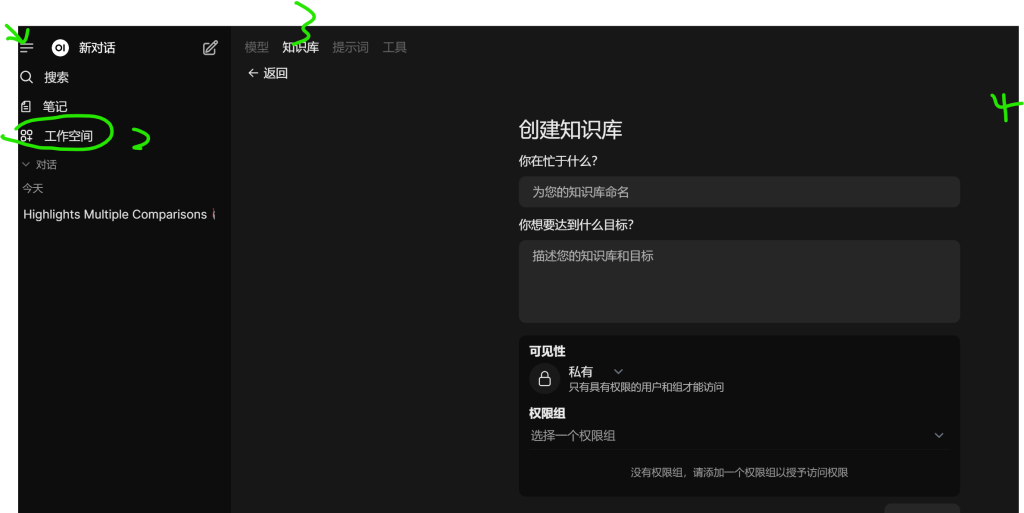

上传文件到具体的知识库
build 自己的模型,需要选择基础模型,权限,知识库,偷懒一起选了
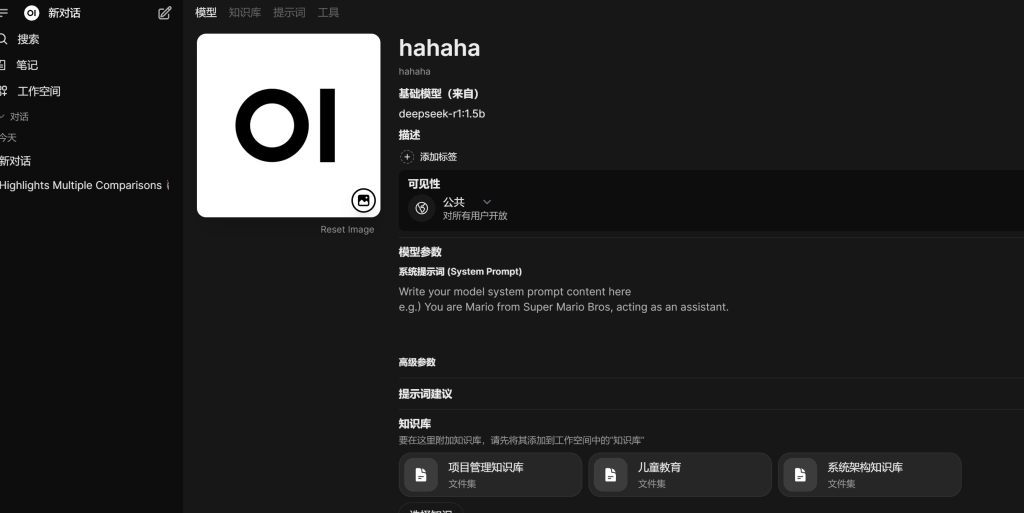
测试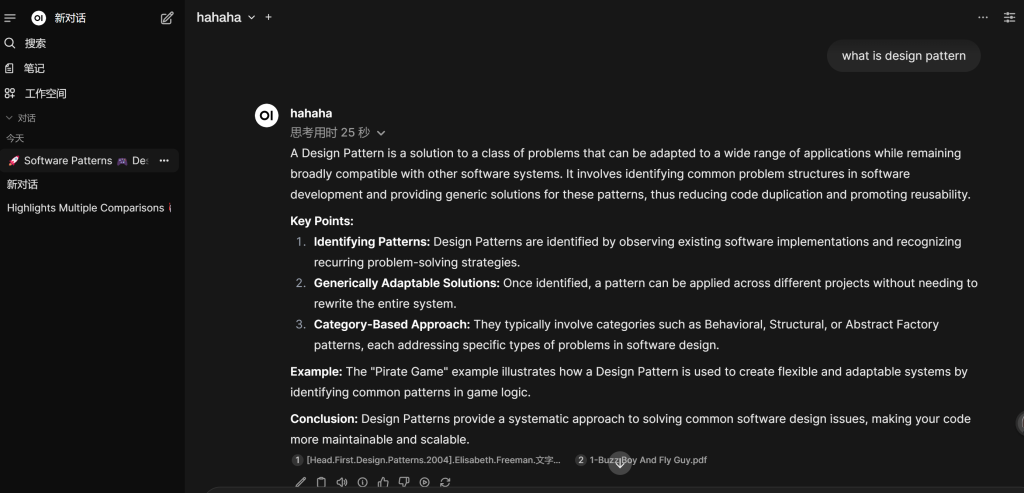
大功告成!
注意事项:
1. 上传文件很慢,因为要进行向量转换,所以笔记本的话就老老实实一个一个传2. 关注一下CPU 和内存
API 的调用方式 后面继续更新….
-
AI 考证课程-第一天的资源
提示词教程:
- LangGPT 结构化提示词
- 🔥中文 prompt 精选🔥,ChatGPT 使用指南,提升 ChatGPT 可玩性和可用性!🚀
- Anthropic 官方提示词库
- DeepSeek 官方提示词库
安装 Docker下载并运行 Open WebUI
docker pull ghcr.nju.edu.cn/open-webui/open-webui:maindocker run -d -p 3000:8080 --restart no -v open-webui:/app/backend/data --name open-webui ghcr.nju.edu.cn/open-webui/open-webui:main如果有cuda:
docker run -d -p 3000:8080 --gpus all --restart no -v open-webui:/app/backend/data --name open-webui ghcr.nju.edu.cn/open-webui/open-webui:cudaOllama 把模型安装在其D盘
创建模型存储文件夹:在 D 盘创建一个用于存放 Ollama 模型的文件夹,例如 “D:\OllamaAI”。
设置环境变量:在系统设置中搜索 “系统变量” 并进入相关设置页面。在 “系统变量” 下方点击 “新建”,创建一个新的环境变量。变量名设置为 “OLLAMA_MODELS”,变量值设置为刚才在 D 盘创建的文件夹路径 “D:\OllamaAI”,点击 “确定” 保存设置。
重启电脑:使环境变量设置生效。
下载模型:重启后,按快捷键 Win+R,输入 “cmd” 并确定,打开命令提示符窗口。输入 “ollama run + 模型名称”,然后按回车键开始下载模型,例如 “ollama run deepseek – r1:7b”。下载完成后,模型会存储在 D 盘指定的文件夹中。
ollama 安装
下载链接:https://ollama.com/downloadpip install ollama💻 动手学 Ollama 🦙:https://datawhalechina.github.io/handy-ollama/
- miniconda 下载链接:https://www.anaconda.com/download/success
- 配置镜像:https://mirrors.tuna.tsinghua.edu.cn/help/anaconda/
- 文档: