数据库集群架构一般如下
一主多从
主从同步
读写分离
主从同步有延时,就可能读到脏数据
解决方案有四种
- 忽略,如果业务上能接受
- 半同步复制,主库写数据之后,等待binlog 同步之后才返回请求,但是明显写请求延时会增加
- 强制读主, 强大的主库 + 缓存, 从库只用来进行数据备份
- 选择性读主库,写的时候,把库+表+key 写到缓存,超时设置为数据同步时长,查询的时候先查这个组合是否在写,如果在写,则强制读主库,否则可以读从库。
数据库集群架构一般如下
一主多从
主从同步
读写分离
主从同步有延时,就可能读到脏数据
解决方案有四种
七大核心维度
Role(角色) – Task(任务) – Tone(语气) – Context(背景) – Format(输出格式) – Criteria(验收) – Iteration(迭代方向)
角色- Role: 明确 AI 在交互中的身份设定,决定输出的专业立场与行为模式
角色:你是经济学领域的文献综述专家
任务:撰写「数字经济对就业市场影响」的文献综述框架
背景:已收集2019-2024年中英文文献50篇,重点关注中国市场
语气:严谨客观,采用学术规范表述
输出格式:思维导图(需包含理论基础、影响机制、争议焦点、研究空白4个主模块)
评估标准:框架需覆盖至少80%已收集文献的研究视角,争议焦点部分需列出至少3种对立观点
迭代指令:完成后请补充「政策建议」子模块,并标注每个建议对应的理论依据角色:你是新零售业态创新顾问
任务:为传统超市设计数字化转型方案
背景:超市位于二线城市核心商圈,面积2000㎡,目标客群年龄35-55岁,2023年线上订单占比仅8%
语气:务实可行,突出投入产出比
输出格式:PPT提案(包含现状分析、改造方案、投资回报表3个部分)
评估标准:方案需实现线上订单占比提升至30%,改造成本控制在500万元以内
迭代指令:先提交3个方向的创意简报,经筛选后再展开详细方案
角色:你是科幻小说作家,擅长硬科幻与社会伦理结合的题材
任务:创作一个关于「记忆移植技术」的短篇故事开头
背景:设定在2045年的智慧城市,记忆移植已成为治疗心理创伤的常规手段,但存在伦理争议
语气:冷峻细腻,兼具科技质感与人文关怀
输出格式:小说片段(300-500字),需包含场景描写、主角心理活动、技术细节暗示
评估标准:需在开头50字内建立世界观悬念,技术描述需符合认知科学基本原理
迭代指令:提供A版本(主角接受记忆移植)和B版本(主角拒绝移植)两个开头
反事实推理是Deepseek 的核心技术之一, 通过构建与事实相反的假设性情景,来探索因果关系和潜在结果的逻辑推理方法。
反事实推理有着严密的数学模型,基于因果推断三层次模型,由美国计算机科学家 Pearl 提出。
因果推断三层次分别为关联、干预和反事实。
关联层关注条件概率,能发现变量间相关性,但无法确定因果性;
干预层关注主动干预某一变量后对结果的影响;
反事实层则研究假设性问题,关注如果采取了不同的行动,结果会如何,会用到结构因果建模、反事实计算、可识别性分析等知识。
参考deepseek 的反事实推理的逻辑,我们来看CREATE 框架
Contrast: 要求多方案比较
Risk Aware: 要求评估潜在风险
Experimental: 要求假设推演
Alternative: 要求备选方案
Trade off: 要求分析优缺点
Explain: 要求说明决策逻辑
火山: https://www.volcengine.com/mcp-marketplace
Trae 里面直接使用 @Build with MCP 可以打开
MCP 市场: http://mcpmarket.cn/
参加LPTC(Life planning training course, Metlife -保险行业的黄埔军校的岗前培训)遇到了一些有趣的灵魂。
先说班主任,老吴, 很严格,即使讲笑话也让大家有压力的感觉~
培训部的主管朱总,做保险就是做人,让客户愿意与你交流。
个业务部门的主管们,各领风骚吧。崔A,不买保险因为不了解,很有激情和感染力。陈昊东,我的主管,个儿最高。沈总,来自互联网的大佬,不记得他讲了什么了,感觉就很忙。
讲师:史宏萍总,很和善,乐于发积分卡,于是课堂很热烈。
罗小燕总,来自证券咨询的大佬,26个月升A,教授了如何通过学,做,复制的模式实现自己的职业目标。 我们担心跨界的失败,更多是相信的力量不够。
五组的小伙伴们:
邹有:来自多年建筑行业的女孩,喜欢查理芒格
唐馨:从事广告设计多年,服务过比亚迪,蔚来汽车等大客户
唐培德: 喜欢带娃和养生的大男孩
顾烨荣: 五组的big bang,班级最壮的大哥大,卷够了大厂,喜欢养生
齐文玥:海归审计师
夜训的老大:韩陆总,分享了超多干货,很风趣。上篇的干货大半来自韩总。
学习, 总是能遇到让自己开心起来的理由。加油,明天!
你有没有遇到过想买保险,但是未来那么多不确定,不知道从哪里开始买?
有没有遇到过,资金有限,买了一个保险之后后悔应该买另外一个?
那么我们应该怎么买保险呢?
下面的分析主要来源于大都会人寿的Agency Director: 韩陆
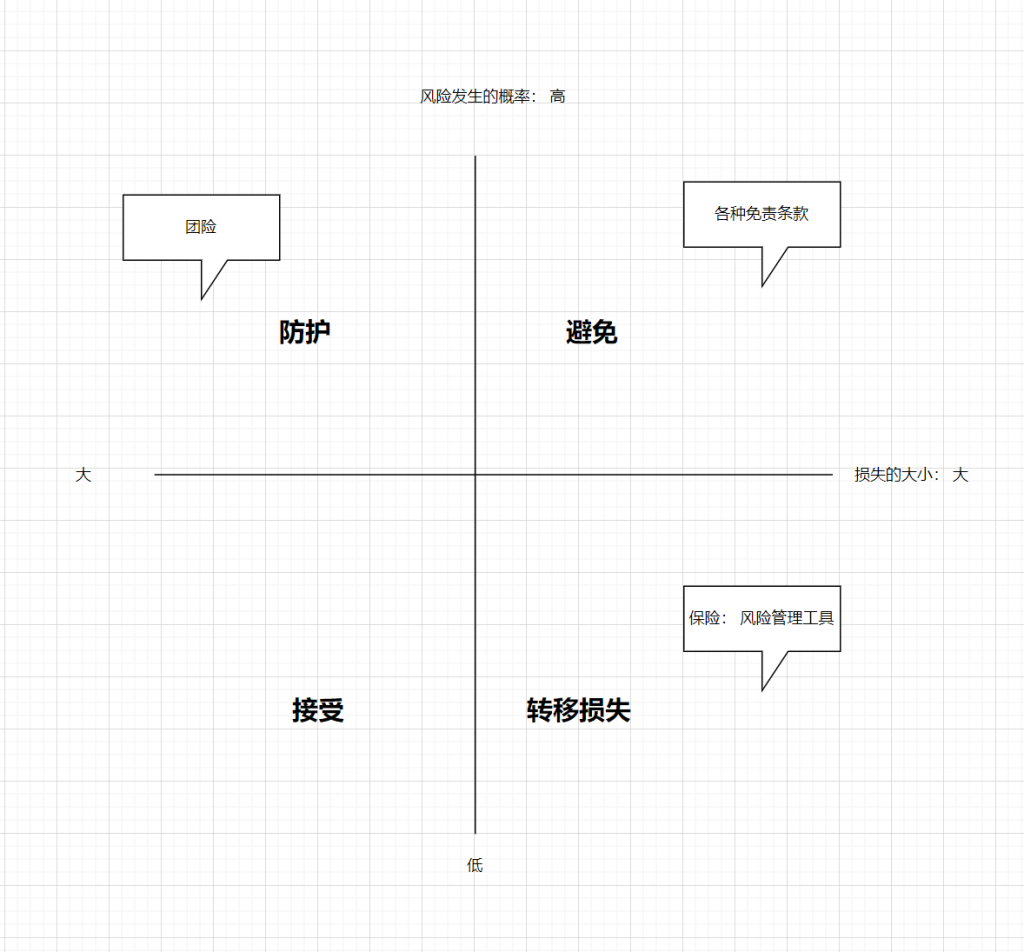
回答这个问题,先要理清楚保险保障的风险种类。
大病(72.18%), 意外伤残, 死亡(100%),养老(84%)
()中的是人一生中遇到这个情况的概率
人一生中得大病重疾的概率高达72.18%, 死亡的概率是100%, 能活到60岁养老的只有84%,早亡的16%里面, 有12%是病故,4%是意外。(基于最近的统计数据)
购买的逻辑
那么有了种类,我们得寻找一个逻辑主线: 时间发生的先后
对于能买保险的您来说,明天不会发生的是什么? 是不是养老,于是我们把养老放到第四位
剩下是不是死亡? 我们需要把死亡分成早亡(16%) 和驾鹤西去(财富传承)两个类型分开谈。
对于驾鹤,一般是不是在养老后面? 于是我们把财富传承放到第5位。
那么早亡跟大病,意外的顺序呢?
参考我们上面的分析,早亡的原因是疾病和意外,于是早亡变成了第三名。
剩下的是大病和意外伤残了。按照发生的概率,大病更容易发生,所以大病排第一,意外排第二。但是通常意外会有大的杠杠,比如低保费高保额,所以通常采用大病和意外组合的方案。
于是我们得到了下面的优先级
(大病重疾,意外伤残), 早亡, 养老, 财富管理
我们再回忆一下自己买的保险,如果把有限的钱配置在低级别的产品上,是不是更容易后悔?
一个小问题: 孩子的教育金应该排在哪?
购买保险的原则
其他一些比较有意思的点:
保险究竟保的是哪些风险?
保险是骗人的吗?
工具本身会骗人吗?对保险的误解来自于信息差
比如地震,财险的地震是免责条款,寿险是可以理赔的
比如自杀,寿险要求两年之后,经过了两年,当时轻生的念头还在吗?
比如大街上走路突然摔倒了,算意外吗?从保险条款的描述上,一般是不算的~
保险公司的收益究竟从哪里来的?三差
| 三差类型 | 对比维度 | 盈利条件 |
|---|---|---|
| 死差 | 实际死亡率 vs 预定死亡率 | 实际死亡率 < 预定死亡率 |
| 利差 | 实际投资收益率 vs 预定利率 | 实际投资收益率 > 预定利率 |
| 费差 | 实际费用率 vs 预定费用率 | 实际费用率 < 预定费用率 |
保险公司的养老保险为什么能做到年化 4% 以上? 现在一年期的定期存款利率才 1%。
资金运作的 “时间杠杆”
久期匹配下的收益积累
AI 正在重塑组织结构,尤其是中层管理着,那么哪些工作更容易被AI替代,我们要具备哪些能力,要进行怎样的思维转变来拥抱AI新时代。 (PPT 来自于复旦大学管理学院 刘圣明教授)
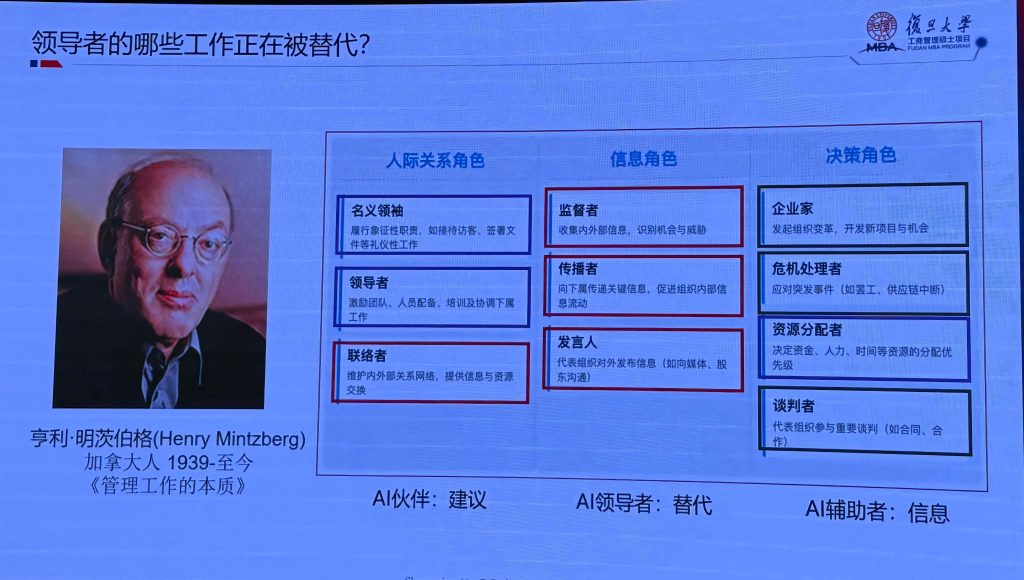
红色的部分正在被AI替代,这些工作偏事务性,作为管理者,我们要更focus 蓝色部分的工作。

这一页感触比较深,项目经理是技术,AI 与业务之间的纽带,对AI技术影响的敏感性,更开放地去拥抱变化,是我们核心的能力
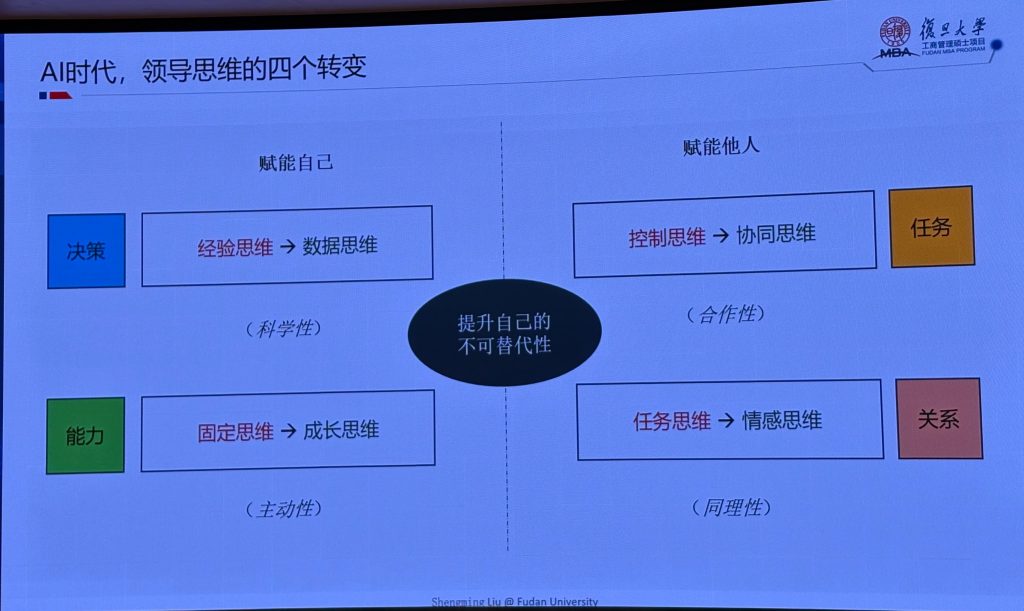
数据思维决策
成长性思维
协同赋能他人
情感优于任务


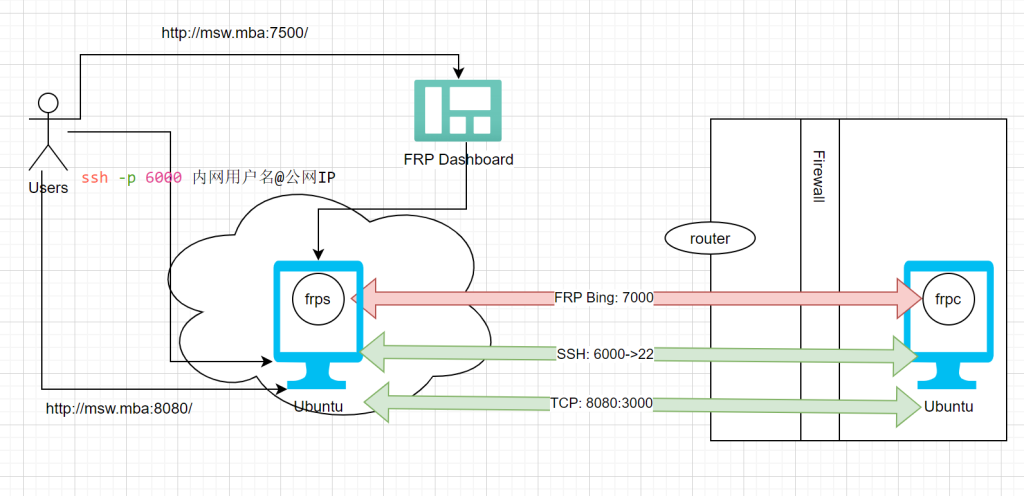
前提条件:云端有ubuntu服务器,且开启公网访问,防火墙开启 7000 + 其它端口,如图中6000(ssh), 7500(dashboard),8080(应用端口)
内网机器可以是Ubuntu,也可是是windows
通过FRP 7000端口,FRP client 与 FRP 服务端建立连接
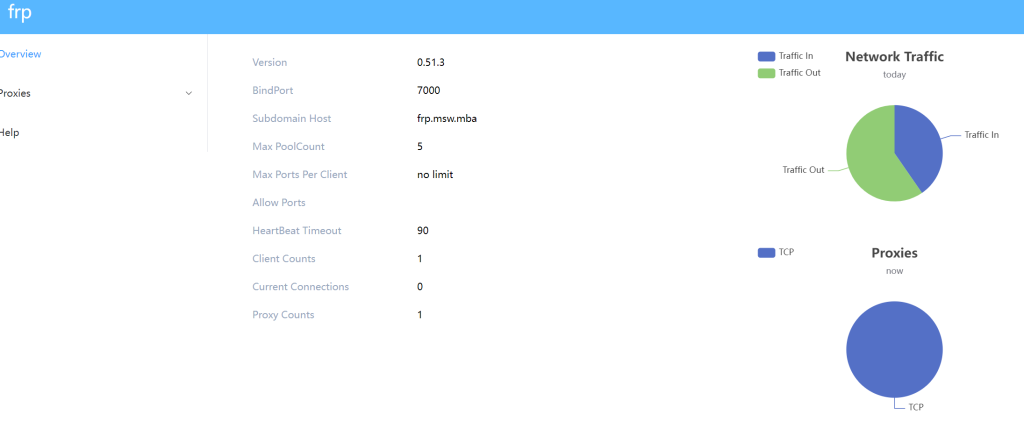
FRP 在server 端通过端口7500,提供Dashboard 来监控网络情况
如图,其他应用通过在client 端配置端口映射来个服务端建立连接
用户可以通过云端的服务器域名/IP:port 的方式来访问部署在内网的应用,比如Deepseek 本地模型部署 (这个后面单独写一篇)
安装教程:
云端:
1. 安装FRP
wget https://github.com/fatedier/frp/releases/download/v0.49.0/frp_0.49.0_linux_amd64.tar.gz
tar -zxvf frp_0.49.0_linux_amd64.tar.gz
cd frp_0.49.0_linux_amd642. 配置服务端
[common]
bind_port = 7000 # 服务端与客户端通信端口(默认7000,可自定义)
dashboard_port = 7500 # 仪表盘端口(默认7500,可自定义)
dashboard_user = admin # 改成自己的
dashboard_pwd = admin # 改成自己的
# 可选:设置日志级别
log_level = info
log_max_days = 33. 启动服务端服务
# 前台运行(测试用)
./frps -c frps.ini
# 后台运行(推荐)
nohup ./frps -c frps.ini &4. 开启防火墙
# UFW防火墙示例(放行7000,7500,8080端口)
sudo ufw allow 7000/tcp
sudo ufw allow 6000/tcp
sudo ufw allow 7500/tcp
sudo ufw allow 8080/tcp本地:
wget https://github.com/fatedier/frp/releases/download/v0.49.0/frp_0.49.0_linux_amd64.tar.gz
tar -zxvf frp_0.49.0_linux_amd64.tar.gz
cd frp_0.49.0_linux_amd642. 配置FRP
[common]
server_addr = 云端服务器公网IP # 替换为云端Ubuntu的公网IP
server_port = 7000 # 服务端的bind_port
# SSH转发规则(重点!)
[ssh]
type = tcp # 转发类型为TCP
local_ip = 127.0.0.1 # 本地SSH服务IP(内网Ubuntu的SSH地址,通常是127.0.0.1或内网IP)
local_port = 22 # 本地SSH端口(默认22)
remote_port = 6000 # 云端服务器映射的公网端口(可自定义,需与服务端防火墙放行)
[web]
type = tcp # Web应用通常使用TCP协议
local_ip = 127.0.0.1 # 内网Web应用所在IP(通常是本机)
local_port = 3000 # 内网Web应用端口
remote_port = 8080 # 云端服务器映射的公网端口(自定义,需确保未被占用)3. 启动客户端服务
# 前台运行(测试用)
./frpc -c frpc.ini
# 后台运行(推荐,需创建systemd服务)
# 1. 创建服务文件
sudo nano /etc/systemd/system/frpc.service4. 配置系统服务,允许自动启动
修改frpc.ini 文件
[Unit]
Description=frp client
After=network.target
[Service]
Type=simple
User=root
ExecStart=/path/to/frpc -c /path/to/frpc.ini # 替换为实际路径
Restart=on-failure
[Install]
WantedBy=multi-user.target保存后启动服务
sudo systemctl daemon-reload
sudo systemctl start frpc
sudo systemctl enable frpc # 开机自启测试
云端通过7500端口访问Dashboard
云端通过6000 端口ssh 内网机器
云端通过8080 端口访问web服务
改进:配置安全连接(两端都需要配置)
# 服务端(frps.ini)
[common]
token = your_secure_token # 设置连接密钥,增强安全性
# 客户端(frpc.ini)
[common]
token = your_secure_token # 与服务端一致
compress = true # 启用数据压缩,减少流量碰到一个无语的bug,调了半天…
一切正常,没有server 错,没有cors 错, 如图
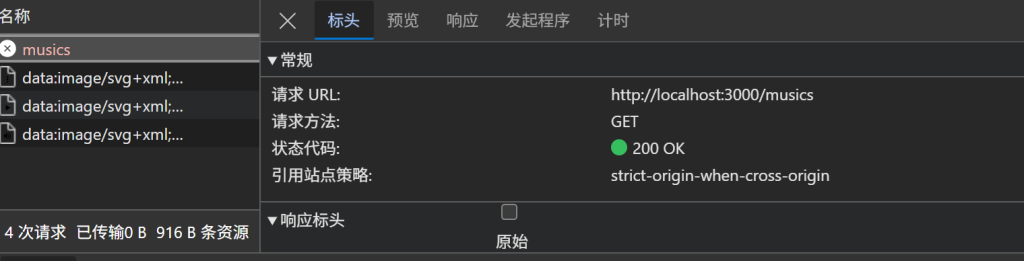
但是就是没有数据

折腾,折腾,再折腾…
回滚到线上版本还是不行,奇了怪了
不卖关子啦,原来我开的地址是: 127.0.0.1
但是 在cors 的白名单里面,配的是localhost
改过来就正常了…

听了8节免费课,感觉懂了点,又感觉没懂!先记下来
什么是深度学习 – 深度神经网络的权重参数学习
从系统论来看,万事万物可以看成下面的基础结构(多层感知机)
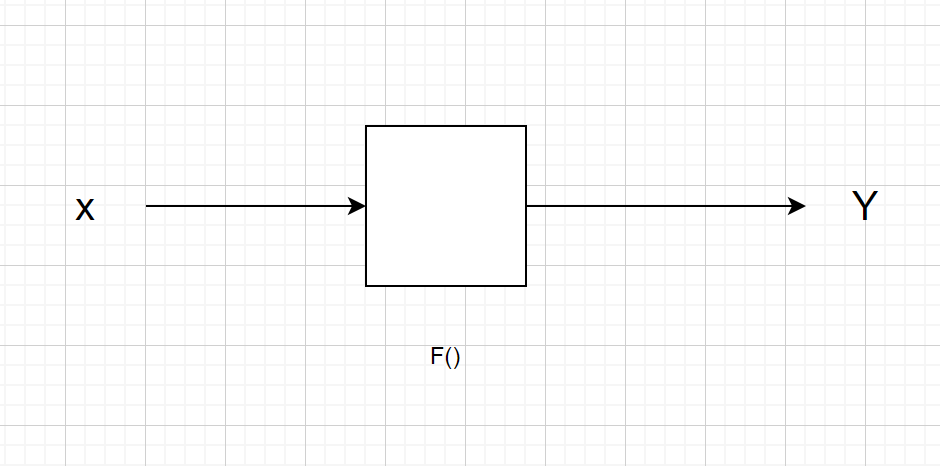
从 Y = f(Wx + b)
到 Y = fnfn-1…fo(Wx + b)
深度学习就是 求这个W
深度就是线性模型外面套激活函数,一层一层来逼近目标
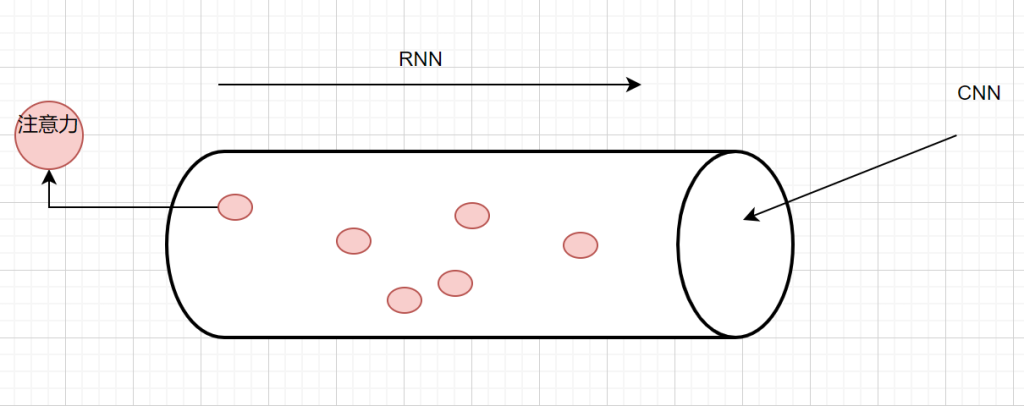
CNN,卷积神经网络->空间维度的一个截面- 把W通过w卷积
RNN:循环神经网络 -> 考虑时间/时序维度的关系
Yn = f(Ux + WYn-1 + B )
注意力网络: Transformer -> 认知科学维度,聚焦关键特征
Y = softmax(QK / [d])V
AIGC
机器视觉 CV
语音
NLP – 文本,以及背后的语义,逻辑,情感,意图等 -> LLM -> AI2.0
多模态 – 多媒体 – 文本,图形,视频,语音的生成和交互
线性代数 – 数据表达 – 前向传播
概率统计 – 损失函数 – 优化引擎
微积分 -链式法则- 反向传播
向量和矩阵:数据在AI领域的数字表达
神经网络的核心操作是线性变换 + 非线性激活,就是前面讲的:输入向量 x 通过权重矩阵 W 完成线性变换 y=Wx+b
卷积神经网络(CNN)中的卷积操作可视为稀疏矩阵乘法,利用局部连接和权值共享减少计算量
AI 模型(如神经网络)通过损失函数(如交叉熵)衡量预测误差,需利用微积分中的导数找到使损失最小的参数。
梯度(Gradient)是损失函数对参数的偏导数向量,指引参数更新的方向(沿梯度反方向更新可最快降低损失)
反向传播算法(Backpropagation)本质是链式法则的应用,递归计算每个参数的梯度,实现端到端的优化。
动量法(Momentum)引入梯度的一阶惯性(类似物理中的动量),通过指数加权平均加速收敛;
Adam 算法结合梯度的一阶矩(均值)和二阶矩(方差),自适应调整学习率,其推导依赖泰勒展开、牛顿法等微积分理论。
为了使用梯度下降优化,激活函数(如 ReLU、Sigmoid、Tanh)必须可导(或近似可导)。
微积分支持对连续变量的建模(如回归问题预测房价、温度等连续值),而离散优化(如组合问题)常通过连续松弛(如将 0-1 变量松弛为 [0,1] 区间的实数)转化为微积分问题求解。
分类模型通过 Sigmoid 函数将线性变换结果映射为概率(如二分类中 \(P(y=1|X) = \sigma(\mathbf{w}^T\mathbf{x})\)),损失函数(交叉熵)对应极大似然估计的优化目标
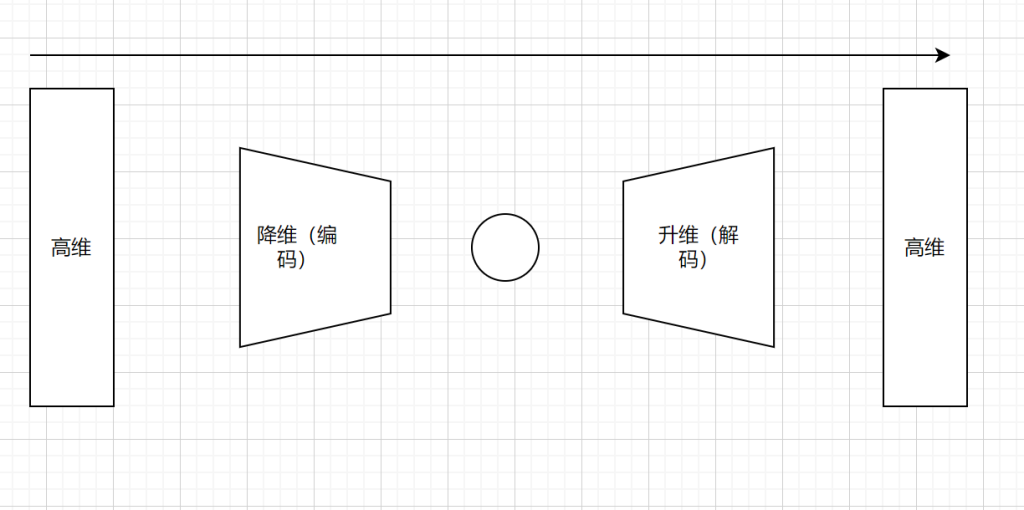
生成模型变分自编码器(VAE)假设隐变量 z 服从先验分布(如标准正态分布),通过编码器 \(q(z|X)\) 近似后验分布 \(p(z|X)\),解码器 \(p(X|z)\) 生成新样本,目标是最大化对数似然的变分下界
归一化流(Normalizing Flow)通过可逆变换将简单分布(如高斯分布)转化为复杂数据分布,利用概率密度变换公式(雅可比行列式)计算似然
多头注意力机制(Multi-Head Attention)通过线性变换(矩阵乘法)将查询(Query)、键(Key)、值(Value)映射到多个子空间,计算注意力权重时使用点积(内积)和 Softmax 函数(归一化概率分布)
位置编码(Positional Encoding)利用正弦余弦函数(微积分中的周期函数)引入序列顺序信息,避免纯线性变换的排列不变性
总结:微积分中的链式法则支撑反向传播算法,而线性代数中的矩阵求导(如雅可比矩阵、海森矩阵)提供参数梯度的计算框架,概率论中的期望运算(如损失函数的数学期望)将样本层面的优化扩展到总体分布。